While language modeling takes up more and more space in AI technologies, we think it is our duty to explain what is Chinchilla AI and how to use it to our valued readers.
Researchers at DeepMind created the Chinchilla model, which has 70 billion parameters and four times as much data as Gopher but the same computing budget. Chinchilla’s performance is noteworthy not just for the size of the improvement, but also because it is smaller than any other major language models created in the previous two years that demonstrated SOTA performances.

Chinchilla consistently and significantly outperforms Gopher (280B), GPT-3 (175B), Jurassic-1 (178B), and Megatron-Turing NLG on a variety of downstream evaluation tasks (530B). It uses substantially less computing for inference and fine-tuning, which greatly increases downstream use. Do you wonder what is Chinchilla AI? Let’s investigate it in this article.



What is Chinchilla AI?
Let’s start by understanding what is Chinchilla AI before learning how to use Chinchilla AI. Recent language modeling challenges have tended to increase model complexity without increasing the number of learning tokens (around 300 billion throughout training). The largest transformer model at this time is the Megatron-Turing NLG, which is more than three times larger than OpenAI’s GPT-3. DeepMind has presented a brand-new language model called Chinchilla.
There is one significant difference, even though it performs similarly to large language models like Megatron-Turing NLG (530B parameters), Jurassic-1 (178B parameters), GPT-3 (175B parameters), Gopher (280B parameters), and GPT-3: With just 70 billion parameters and four times as much data as Gopher, it achieves an average accuracy of 67.5 percent on the MMLU benchmark, which is a 7 percent improvement over Gopher.
How To Use Chinchilla AI?
Now that we explained to you what is Chinchilla AI let us jump to answering your how to use Chinchilla AI questions but we have some bad news for you. Unfortunately, the general public cannot currently access it. Chinchilla AI will eventually be accessible in the coming months, at which point you can use it to develop chatbots, virtual assistants, predictive models, and other AI applications.
Chinchilla achieved a cutting-edge average accuracy of 67.5 percent on the MMLU benchmark, outperforming Gopher by 7 percent. The common strategy in big language model training has been to build the model without growing the supply of training tokens. The biggest dense transformer, MT-NLG 530B, is now more than three times bigger than the 170 billion characteristics of GPT-3.
Chinchilla AI is going to be a dominant force in language modeling
Now that we have answered your question What is Chinchilla AI and how to use it, let’s talk about AI technologies in general.
Growing the model without growing the number of training tokens has been the prevalent approach in large language model training. In comparison to the 170 billion characteristics of GPT-3, the largest dense transformer, MT-NLG 530B, is now over 3 times larger.
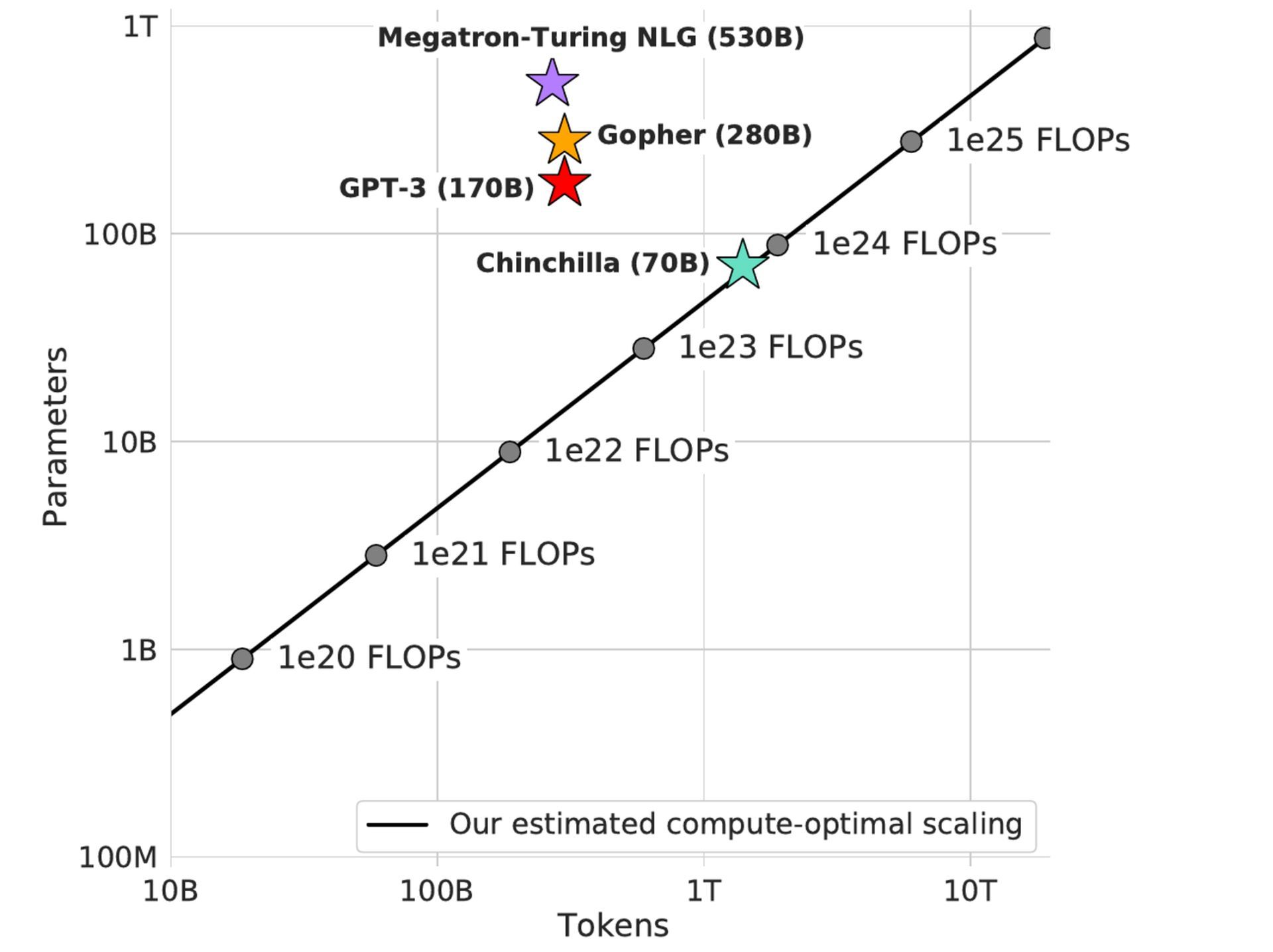
The majority of large models now in use, including DeepMind’s Chinchilla, have all been trained for over 300 billion tokens. The race to train larger and larger models is producing models that, according to the researchers, are significantly underperforming when compared to what could be accomplished with the same computing budget. This is true even though the desire to train these mega-models has significantly advanced engineering.
Chinchilla AI features that will overcome the computing budget
The limiting factor in AI technologies is typically the compute budget, which is independent and known in advance. The amount of money the corporation can spend on better hardware will ultimately define the size of the model and the number of training tokens. To overcome this issue Chinchilla AI features:
- Fixed model size: DeepMind programmers created a family of fixed model sizes (70M-16B) and adjusted the number of training tokens for each model (4 variations). The best combination for each compute budget was then identified. According to this method, a model trained with the same amount of computing power as Gopher would have 1.5T tokens and 67B params.
- Curves for isoFLOP: Engineers at DeepMind experimented with model size and fixed compute budget. This method would result in a compute-optimal model with 63 billion parameters and 1.4 trillion tokens, trained with the same amount of computing as Gopher.
- Creating a parametric loss function: DeepMind engineers modeled the losses as parametric functions of the model size and token count using the findings from methods 1 and 2. The compute-optimal model trained using this method would have 40B parameters and the same amount of computation as Gopher.
If you are curious, you can examine DeepMind’s approach to the subject from the paper they published.
We are coming to the end of our article where we answered the questions of What is Chinchilla AI and how to use it as best we can for you. While language modeling technologies have managed to become the most prominent AI sub-category in 2022, we wonder what awaits us in 2023.