
Today we are going to talk about hashing algorithms and what are they used for. A cryptographic hash function is a mathematical algorithm that transforms any incoming data into a series of output characters, with a fixed or variable length, depending on the hashing algorithm being used. In hashing algorithms with fixed output length, this length will be the same regardless of the size of the input data. Hashing algorithms that are specifically designed to protect passwords are usually variable.
What hashing algorithms are used for?
Hashing algorithms are mainly used to protect passwords and not to store them in clear text in a database. If you’ve ever read anything about hash functions, chances are it was about their main use, protecting passwords from being stored in cleartext. Imagine that cybercriminals are able to breach a service and steal your database, if passwords were not hashed, your credentials would be exposed immediately.
To check that we have correctly entered a password that is stored in a database (the hash of the key is stored), what is done is to apply the hashing algorithm to the password entered and compare it with the stored one. If it is the same, the key is correct, if it is different, the key is incorrect. This procedure is used in all operating systems, websites with user/password authentication, etc.



If you ever have to recover or retrieve your password from any online service, you will have to reset it, because even the service itself will not be able to provide you with the password in clear text, but will only store the password hash. If you have asked service to retrieve your password, and they offer it to you in plain text, that means that they store it that way, and it is not safe to use that service. Although the typical 123456 passwords have well-known hashes, as soon as we put a strong password, it will not be in any online hash cracking system, and we will have to crack it ourselves with tools such as Hashcat among others.
Not all uses of hashing algorithms are for passwords, hashing algorithms are also used to detect malware, they can be used to detect different copyrighted songs or movies, and create blacklists. There are also public lists of malware, they are known as malware signatures, they are made up of hash values of whole or small pieces of malware. So, if on the one hand, a user detects a suspicious file, he can consult these public hash databases, and thus, know if it is a malicious file or if it has no danger, in turn, on the other hand, also serve for antivirus to detect and block malware by comparing the hashes of their own databases and the public ones we talked about.
Another important use of hashing algorithms is to ensure the integrity of messages. The way to use them for this purpose is to check the hashes created before and after the data transmission, thus, if the hashes are completely identical it means that the communication has been secure and that the data have not been altered, otherwise, something has gone wrong in the middle and the data obtained at the end of the communication are not the same as those that were issued at the beginning.
Now that we know all about hash functions, let’s see which ones are most commonly used today.
What are the most common hashing algorithms?
SHA2
The SHA algorithm (Secure Hash Algorithm) was originally created by the NSA and NIST with the aim of generating unique hashes or codes based on a standard. In 1993 the first SHA protocol, also called SHA-0, was born, but it was hardly used and did not have much impact. A couple of years later, an improved, stronger and more secure variant, SHA-1, was released, which has been used for many years to sign SSL/TLS digital certificates for millions of websites. A few years later SHA-2 was created, which has four variants depending on the number of output bits, namely SHA2-224, SHA2-256, SHA2-384 and SHA2-512. Currently, for security reasons, SHA1 is no longer used, but it is highly recommended to use SHA2 or SHA3 (within the SHA family).
How SHA2 works?
Hashing algorithms only work in one direction, we can generate the hash of any content or the fingerprint, but with the hash or fingerprint, there is no way to generate the initial content. The only way to do it is by dictionary or brute force, so it could take us thousands of years (currently) to get the initial information.

Among the many different ways to create hashes, the SHA2-256 algorithm is one of the most used solutions thanks to its balance between security and speed, it is a very efficient algorithm and has a high resistance to collisions. This is something very important to maintain the security of this hashing algorithm. For a hashing algorithm to be secure, no collisions must be known. For example, the method of verifying Bitcoins is based on SHA2-256.
Characteristics of the different types of SHA2
- Output size: the size of characters that will form the hash.
Internal state size: it is the internal hash sum, after each compression of a data block. - Block size: the size of the block handled by the algorithm.
Maximum message size: is the maximum size of the message on which we apply the algorithm. - Word length: it is the length in bits of the operation applied in each round by the algorithm.
- Interactions or rounds: the number of operations performed by the algorithm to obtain the final hash.
- Supported operations: the operations performed by the algorithm to obtain the final hash.
SHA-256
It has an output size of 256 bits, an internal state size of 256 bits, a block size of 512 bits, the maximum message size it can handle is 264 – 1, the word length is 32 bits, and the number of rounds it applies is 64, as well as the operations it applies to the hash, are +, and, or, xor, shr and rot. The length of the hash is always the same, no matter how large the content you use to generate the hash: whether it is a single letter or a 4GB ISO image, the result will always be a succession of 40 letters and numbers.
SHA2-384
This algorithm is different in terms of features, but its operation is the same. It has an output size of 384 bits, an internal state size of 512 bits, a block size of 1024 bits, the maximum message size it can handle is 2128 – 1, the word length is 64 bits, and the number of rounds applied is 80, as well as the operations it applies to the hash, are +, and, or, xor, shr and rot. This algorithm is a more secure version than SHA2-256 since more rounds of operations are applied and it can also be applied on more extensive information. This hashing algorithm is often used to check message integrity and authenticity in virtual private networks. On the downside, it is somewhat slower than SHA2-256, but in certain circumstances, it can be a very good option to use this one.
SHA2-512
As in all SHA2, the operation is the same, changing only one feature. It has an output size of 512 bits. The rest of the features are the same as SHA2-384. 512 bits of internal state size, 1024 bits of block size, 2128 – 1 for the maximum message size, 64 bits of word length, and are 80 the number of rounds applied to it. This algorithm also applies the same operations on each round +, and, and, or, xor, she, and rot.
SHA2-224
We have not mentioned this algorithm as the main one, the SHA2-256 is much more widely used since the computational difference between the two is negligible and SHA2-256 is much more standardized. We mention it because, at least so far, no collisions have been found for this algorithm, which makes it a safe and usable option.
SHA-3
SHA3 is the hashing algorithm that belongs to the newer SHA family, it was released by the NISH in 2015, but it is not yet being widely used. Although it is part of the same family, its internal structure is quite different. This new hashing algorithm is based on “sponge construction”. This sponge construction is based on a random function or random permutation of data, it allows any amount of data to be input and any amount of data to be generated, furthermore, the function is pseudo-random with respect to all previous inputs. This allows SHA-3 to have great flexibility, the goal is to replace SHA2 in typical TLS or VPN protocols that use this hashing algorithm to check data integrity and data authenticity.
SHA-3 was born as an alternative to SHA2, but not because using SHA-2 is insecure, but they wanted to have a plan B in case of a successful attack against SHA2, in this way, both SHA-2 and SHA-3 will coexist for many years, in fact, SHA-3 is not massively used as SHA-2.

Characteristics of the SHA3
SHA-3 uses a “sponge” construction, the data is “absorbed” and processed to display output with the desired length. In the data absorption phase, the XOR operation is used and then transformed into a permutation function. SHA-3 allows us to have additional bits of information, to protect the hash function from extension attacks, something that happens with MD5, SHA-1, and SHA-2. Another important feature is that it is very flexible, making it possible to test cryptanalytic attacks and use it in lightweight applications. Currently, SHA2-512 is twice as fast as SHA3-512, but the latter could be implemented through hardware, so then it could be just as fast and even faster.
KDF Hashing Algorithms
The difference between KDF (Key Derivation Function) and a password hash function is that the length with KDF is different, while a password hash function will always have the same output length. Depending on whether we are hashing encryption keys or passwords stored in a database, it is advisable to use some hashing algorithms or others. For example, in the case of stored passwords, it is recommended that the hashing algorithm takes a time of say 5 seconds to calculate, but is then very robust and very expensive to crack.
Less experienced developers who do not know all the possibilities of KDF hashing algorithms will think that fixed-length, collision-resistant, generic one-way cryptographic hash functions such as SHA2-256 or SHA2-512 are better, without thinking twice about the potential problem they may have. The problem with fixed-length hashes is that they are fast, which allows an attacker to crack the password very quickly with a powerful computer. Variable-length hashes are slower, this is ideal for password crackers to take longer to obtain the password.
The cryptographic community came together to introduce hash functions designed specifically for passwords, where a “cost” is included. Key derivation functions were also designed with a “cost”. Based on password-based key derivation functions and hash functions designed specifically for passwords, the community designed several algorithms for use in password protection.
The most popular algorithms for password protection are:
- Argon2 (KDF)
- scrypt (KDF)
- bcrypt
- PBKDF2 (KDF)
The main difference between a KDF and a password hash function is that the length with KDFs is arbitrary, and typical password hash functions such as MD5, SHA-1, SHA2-256, SHA2-512 have a fixed-length output.
For password storage, the threat is that the key database is leaked to the Internet, and password crackers around the world work on the hashes in the database to recover passwords.
Taking as an example the storage of passwords in a database, when we log in to access a website, it is always necessary that the hashing of the key is done quickly so that we do not have to be waiting without being able to access it, but this poses a problem, and that is that it could be cracked faster, especially if we use the power of GPUs along with Hashcat.
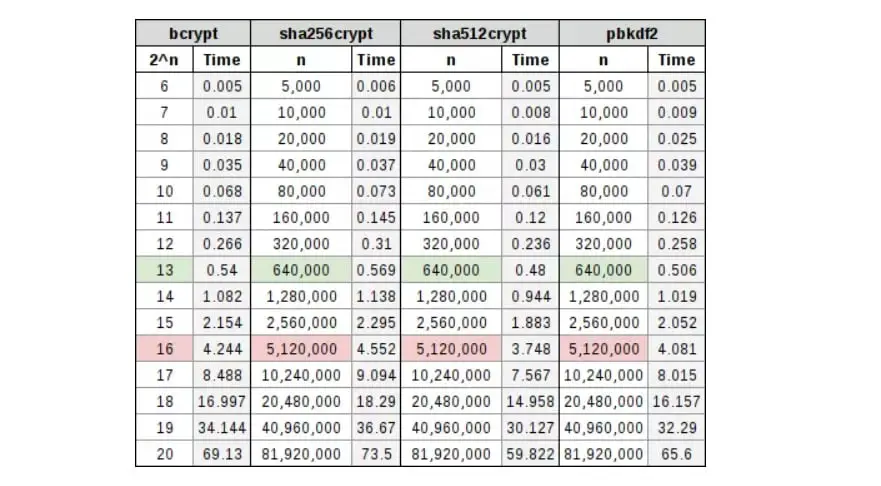
bcrypt, sha256crypt, sha512crypt and PBKDF2
In the following table, there is a comparison of several widely used hashing algorithms, with their corresponding cost in a table. You will see that it is highlighted the green row where a possible work factor could mean spending 0.5 seconds hashing the password, which is a pretty good ratio, and a red row where a possible work factor could mean spending a full 5 seconds to create a password-based encryption key, which is bad because of the loss of efficiency.
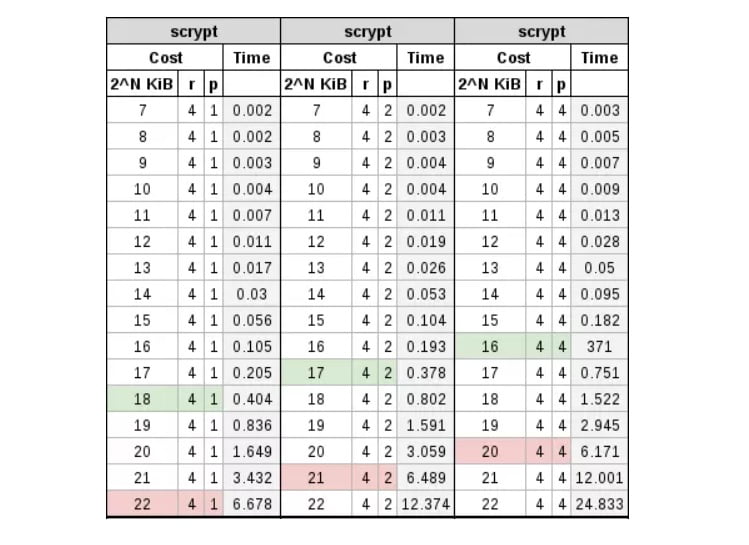
scrypt
When we think about moving to scrypt, it’s because things are getting a little more difficult. With bcrypt, sha256crypt, sha512crypt, and PBKDF2, our cost is entirely a factor of CPU overhead, the more processing power, the more efficient the algorithm. The bad part is that they still fall victim to FPGA and algorithm-specific ASICs. To combat this, a memory cost can be included. With scrypt we will have both a CPU and RAM cost.
In the following table, you can see a comparison with different cost values:
Argon2
Argon2 has two different versions, Argon2d and Argon2i; the former is data-dependent (d) and the latter is data-independent (i). The former is assumed to be resistant to GPU cracking, while the latter is resistant to side-channel attacks. In other words, Argon2d would be suitable for password hashing, while Argon2i would be suitable for encryption key derivation.
Argon2 has a CPU cost and a RAM cost, both of which are handled separately. The CPU cost is handled through standard iterations, as with bcrypt or PBKDF2, and the RAM cost is handled by specifically increasing memory. When testing began with this algorithm, it was found that by simply manipulating the iterations it ended up looking a lot like bcrypt, but in return, the total time it took to compute the hash could be affected by simply manipulating the memory. By combining the two, it was found that the iterations affected the CPU cost more than the RAM cost, but both had a significant share in the computation time, as can be seen in the tables below.
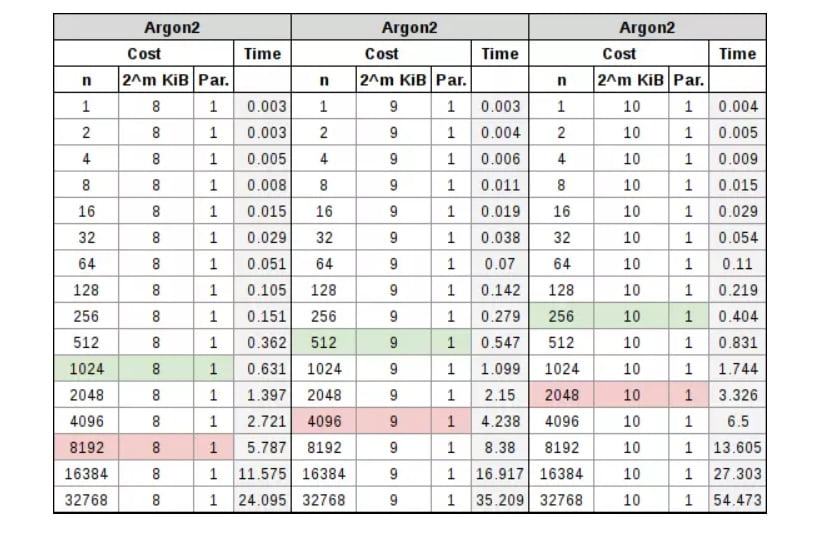
The note to keep in mind in this parameterization process is that the RAM cost varies between 256 KiB and 16 MiB, in addition to the number of iterations and the processor count cost. As we increase the RAM used in the parameterization, we will be able to reduce our iteration cost. As we need more threads to work on the hash, we can further reduce that iteration. So the two concepts being discussed derive in that, independently, we are trying to aim for 0.5 seconds for an interactive password login, and a full 5 seconds for the derivation of the password-based encryption key.
Conclusion
We can summarize the use of these hashing algorithms. When hashing passwords, either to store them on disk or to create encryption keys, password-based cryptography should be used, designed specifically for the problem to be addressed. General-purpose hash functions of any kind should not be used, due to their speed. Also, they should not implement their own “key stretching” algorithm, such as recursive hashing of their password digest and additional output.
So, if we take into account that, if the algorithm was specifically designed to handle passwords, and the cost is sufficient to cover the needs threat model and adversary, then we can say, without a doubt, that we are doing it right. Actually, we will not make a mistake if we choose any of them, we simply have to be clear about the use we are going to give it, so we will avoid any algorithm that is not specifically designed for passwords and thus we will reinforce the security on them.
Now you have a clear idea of what algorithms are used today, we have explained the operation of each algorithm and even the processing costs so that we can be clear about which one to use depending on the situation. What has become clear is that they are all used for a clear common goal, our protection, both fixed hash-based algorithms and variable algorithms are used to protect information because as you know information is power. Thanks to them our passwords, files, and data transmissions are safe from any external threats.



