
Scientists created a new neural network, that can use AI to sing from speech samples. Chinese developers’ algorithm can synthesize a recording of a person’s singing based on a recording of the person’s usual speech, or perform it the other way around and synthesize speech based on singing. An article describing the development, training and testing of an algorithm has been published at arXiv.org.
In recent years, the development of neural network algorithms for speech synthesis, such as WaveNet , has allowed the creation of systems that are difficult to distinguish from real people. For example, in 2018, Google showed a voice assistant for booking seats that can not only speak realistic, but also insert human sounds that make speech verifiable, for example, “um”. As a result, the company also had to teach the algorithm to warn at the beginning of a conversation that it is not a person.
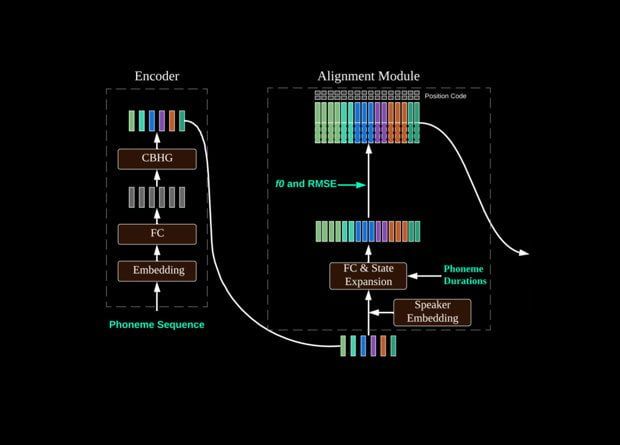


As in the case of other neural network algorithms, the success of speech synthesis systems is largely not related to their architecture, but mostly to the large amount of available data for training. Creating a system for synthesizing singing is a seemingly similar task, but in fact it is much more complicated due to the significantly lower amounts of available data.
Many developers working on singing geneating systems have recently taken the path of reducing the volume of singing samples to teach the algorithm, and now a group of Chinese researchers led by Dong Yu from Tencent have created a system that can create realistic singing audio recordings from speech samples.
https://www.youtube.com/watch?v=AnazWGADtnk
The algorithm is based on Tencent’s previous development, the DurIAN neural network, designed to synthesize realistic videos with a talking presenter based on text. Now they put a new speech recognition unit in front of DuarIAN, which creates phonemes based on the audio sample.



