Microsoft researchers have unveiled a new architecture called Visual ChatGPT, which aims to combine the strengths of natural language processing and image generation. The technology represents a significant breakthrough for text-to-image algorithms, enabling the creation of a more organic and interactive artificial intelligence (AI) experience.
This breakthrough technology could change the face of text-to-image models, which have long struggled with linguistic context. In a paper exploring the relational understanding of generative AI models, researchers found that these models did not “understand” the physical relations of certain objects. Visual ChatGPT could help overcome this limitation, potentially paving the way for future developments in artificial general intelligence (AGI).
You may check out Microsoft’s paper on Visual ChatGPT using the link here.




How does Visual ChatGPT work?
How does Visual ChatGPT work? Essentially, it integrates the capabilities of visual foundation models like Stable Diffusion, ControlNet, and BLIP with the language understanding of ChatGPT. The “prompt manager” acts as an interface between ChatGPT and the visual models, enabling seamless processing of output.
This integration helps to overcome the limitations of both platforms, resulting in a much more capable version of ChatGPT that doesn’t rely on hallucinations, instead leveraging the capabilities of VFMs through the prompt manager.
Here is a diagram on how does Visual ChatGPT works:
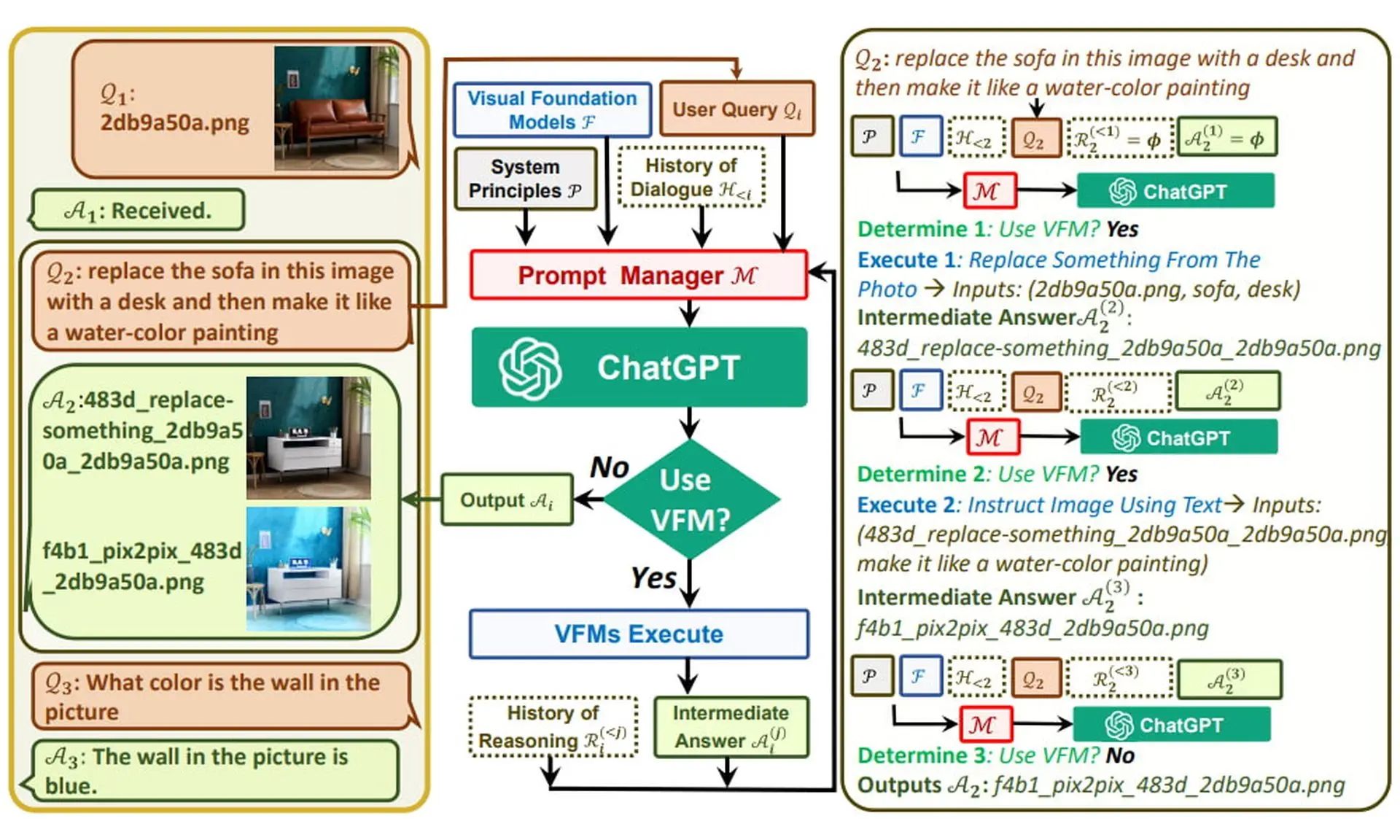
One of the key advantages of Visual ChatGPT is that it allows for sharing images with ChatGPT. The prompt manager acts as a “kitchen manager,” relaying orders and food between the “waiter” (ChatGPT) and the “chefs” (VFMs).
The system also includes a reasoning format, which enables ChatGPT to decide when it needs to use a tool like a VFM to provide the necessary output.
How to use Visual ChatGPT?
Before running the Visual ChatGPT demo, you must follow a few steps as outlined on its GitHub page. Here is what you need to do to run Visual ChatGPT:
conda create -n visgpt python=3.8
# activate the new environment
conda activate visgpt
# prepare the basic environments
pip install -r requirement.txt
# download the visual foundation models
bash download.sh
# prepare your private openAI private key
export OPENAI_API_KEY={Your_Private_Openai_Key}
# create a folder to save images
mkdir ./image
# Start Visual ChatGPT !
python visual_chatgpt.py
Visual ChatGPT is a useful tool that can potentially decrease the learning curve for text-to-image models and enable AI programs to interact with one another. Previous models such as LLMs and T2I models were developed in isolation, but with innovative advancements, their performance can be significantly improved.
There is much anticipation for the release of GPT-4, which is expected to excel in producing images with ChatGPT. However, the release date for this highly awaited model is currently unknown.
New job opportunities AI has been created
As the field of prompt engineering continues to evolve, AI whisperers are emerging as a critical new job category. These professionals work to help AI models “understand” human language and context, enabling more effective natural language processing.
The prompt manager in Visual ChatGPT represents a significant step forward in this field, simplifying the process of conveying information to the model without the need for complex prompts. Therefore, jobs such as prompt engineering become more and more accessible for people who are interested in AI technologies.

Conclusion
Visual ChatGPT is an important development in the field of AI, with the potential to amplify the capabilities of state-of-the-art models. By bringing together the strengths of LLMs and T2I models, it has the potential to reduce barriers to entry and add interoperability to various AI tools.
While there is still much to be learned about the capabilities of Visual ChatGPT and similar technologies, it represents an exciting new frontier in the field of artificial intelligence.