
Based on text prompts, Meta’s MusicGen may create brief new musical compositions that are optionally aligned to an existing tune.
MusicGen is built on a Transformer model, as are the majority of language models used today. MusicGen predicts the next segment of a piece of music in a manner similar to how a language model predicts the following letters in a phrase. The researchers use Meta’s EnCodec audio tokenizer to break down the audio data into smaller pieces. MusicGen is a quick and effective single-stage approach that performs token processing in parallel.
For training, the crew used 20,000 hours of authorized music. They used 10,000high-qualityaudio recordings from an internal dataset as well as Shutterstock and Pond5 music data, in particular.

MusicGen: What is it?
Like the bulk of language models in use today, MusicGen is constructed using a Transformer model. Similar to how a language model predicts the subsequent letters in a sentence, MusicGen predicts the following section of a piece of music.
The audio data is divided into smaller bits using Meta’s EnCodec audio tokenizer by the researchers. MusicGen is a single-stage method that processes tokens quickly and effectively in parallel.
Along with the efficacy of the design and the speed of production, MusicGen is outstanding in its ability to manage both text and musical cues. The music in the audio file follows the basic style established in the text.
You can’t exactly shift the melody’s direction to hear it, say, in other musical genres. It only serves as a broad guide for the generation and is not exactly replicated in the output.
Despite the fact that many other models are running text generation, voice synthesizing, generated visuals, and even small films, there haven’t been many high-quality examples of music production that have been made accessible to the public.

MusicGen: How to use it?
Users may test out MusicGen using the Hugging Face API, but depending on how many users are using it at once, it can take some time to produce any music. You may put up your own instance of the model using the Hugging Face website for much speedier results. You might download the code and run it yourself if you have the required knowledge and tools.
Here’s how to try the online version if, like the majority of people, you want to:
- Launch a web browser.
- Visit the webpage for Hugging Face.
- At the upper right, choose Spaces.
- Search for “MusicGen” in the box.
- Locate the one that Facebook published.
- In the box on the left, type your prompt.
- Choose “Generate”.
That’s everything you need to know!
MusicGen beats MusicLM by a hair
Three distinct sizes of the model—300 million (300M), 1.5 billion (1.5B), and 3.3 billion (3.3B) parameters—were tested by the study’s authors. The 1.5 billion parameter model was judged to be the best by humans, yet they discovered that the bigger models generated sounds of greater quality. On the other hand, the 3.3 billion parameter model performs more correctly when matching text input with audio output.
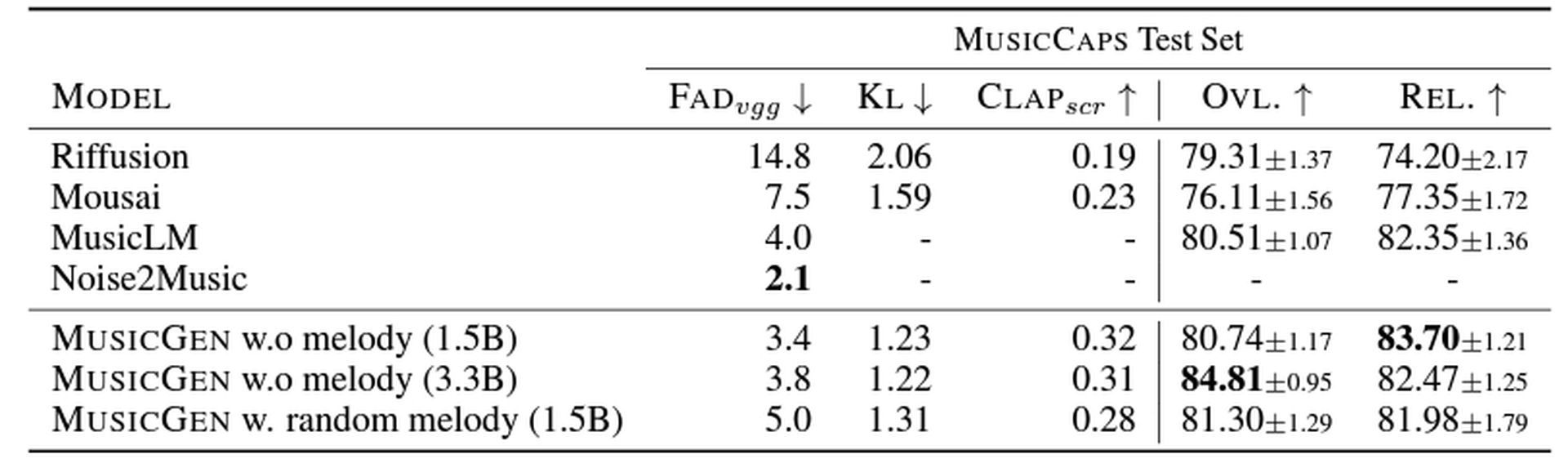
MusicGen scores better on both objective and subjective measures that gauge how well the music matches the words and how believable the composition is compared to other music models like Riffusion, Mousai, MusicLM, and Noise2Music. In general, the models are slightly better than Google’s MusicLM.
The code and models have been made available by Meta as open source on Github, and commercial use is allowed. There is a demo on Huggingface.
Do you know what ChatGPT Shared Links are?




{kind=link}