
Language models have revolutionized various fields with their advanced capabilities, leaving many people with questions like how to use Google MusicLM, and OpenAI’s GPT models, including ChatGPT and Codex, have played a significant role in this disruption. These models have the ability to generate text and code efficiently based on a given prompt. Trained on vast datasets, they can be applied to numerous natural language processing (NLP) tasks, such as sentiment analysis, chatbot systems, summarization, machine translation, and document classification.
While these models have their limitations, they offer a glimpse into the potential of language models to understand languages and develop applications that can enhance human lives. While concerns exist regarding their potential to replace humans in various domains, the underlying idea is to increase productivity and provide new ways to explore and comprehend language as a whole.
Given the fundamental role language plays in human civilization, it becomes imperative to build language models that can decode textual descriptions and perform tasks like generating text, images, audio, and even music. In this article, we will primarily focus on music language models, which are akin to models like ChatGPT and Dall-E, but instead of generating text or images, they are designed to create music.
Music is a complex and dynamic art form. It involves the orchestration of multiple musical instruments that harmonize to create a contextual experience. From individual notes and chords to speech elements like phonemes and syllables, the music encompasses a wide range of components. Developing a mathematical model capable of extracting information from such a diverse dataset is a formidable task. However, once such a model is established, it can generate realistic audio similar to what humans can produce.

With all this in mind, let’s delve into the core concept of music language models and explore how they enable the generation of music. Meanwhile, if you are interested in leveling up your music game, you might also want to check out how to use Discord Soundboard and add new sounds to it.
Understanding music language models and how to use Google MusicLM
MusicLM utilizes various machine learning techniques, such as deep learning and natural language processing, to analyze data and uncover hidden representations that facilitate the generation of music. These models leverage music-specific datasets to extract information, identify patterns, and learn a broad spectrum of musical styles and genres.
MusicLM has the potential to automate a range of tasks, including writing music scores by analyzing existing music, recommending new chord progressions, or even generating novel sounds. Ultimately, it can introduce new forms of musical expression and creativity, serving as a valuable tool for enhancing musicians’ skills and facilitating music education.
Introducing Google MusicLM
Google MusicLM is a dedicated language model designed specifically for generating music based on text descriptions. For instance, by providing a prompt like “a calming guitar melody in a 6/8 time signature riff,” the model can produce corresponding music.
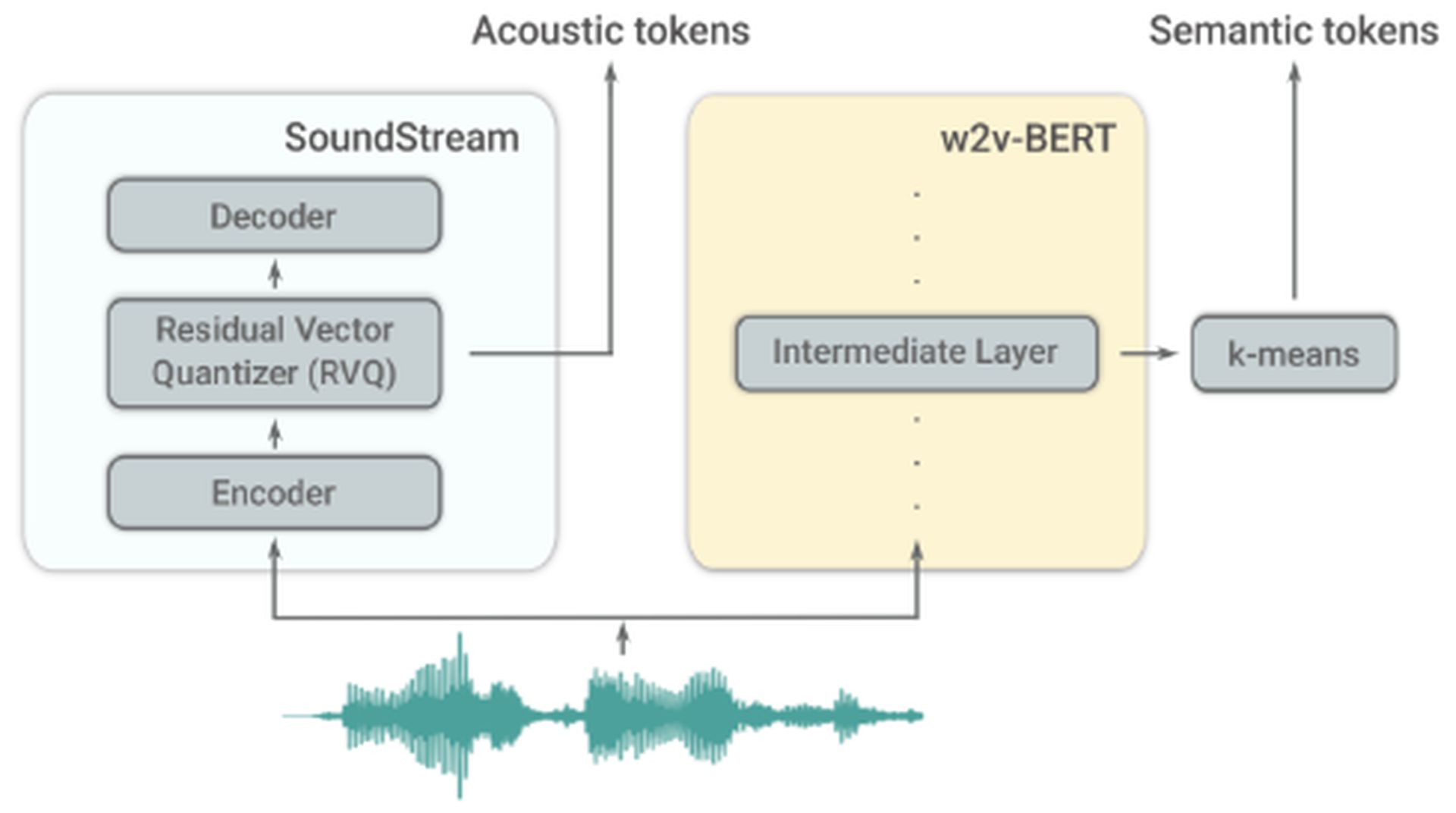
MusicLM builds upon AudioLM, another language model developed by Google. AudioLM focuses on generating high-quality and intelligible speech and piano music continuations. It achieves this by converting input audio into a series of discrete tokens and generating audio sequences with long-term consistency. AudioLM employs two tokenizers: the SoundStream tokenizer, which produces acoustic tokens, and the w2v-BERT tokenizer, which generates semantic tokens. These tokenizers play a crucial role in information extraction.

AudioLM consists of three hierarchical stages:
- Semantic modeling: This stage focuses on capturing long-term structural coherence. It extracts the high-level structure of the input signal.
- Coarse acoustic modeling: Here, the model produces acoustic tokens, which are then concatenated or conditioned on semantic tokens.
- Fine acoustic modeling: The final audio is given more depth in this stage, which involves processing the coarse acoustic tokens with fine acoustic tokens. The SoundStream decoder utilizes these acoustic tokens to recreate a waveform.
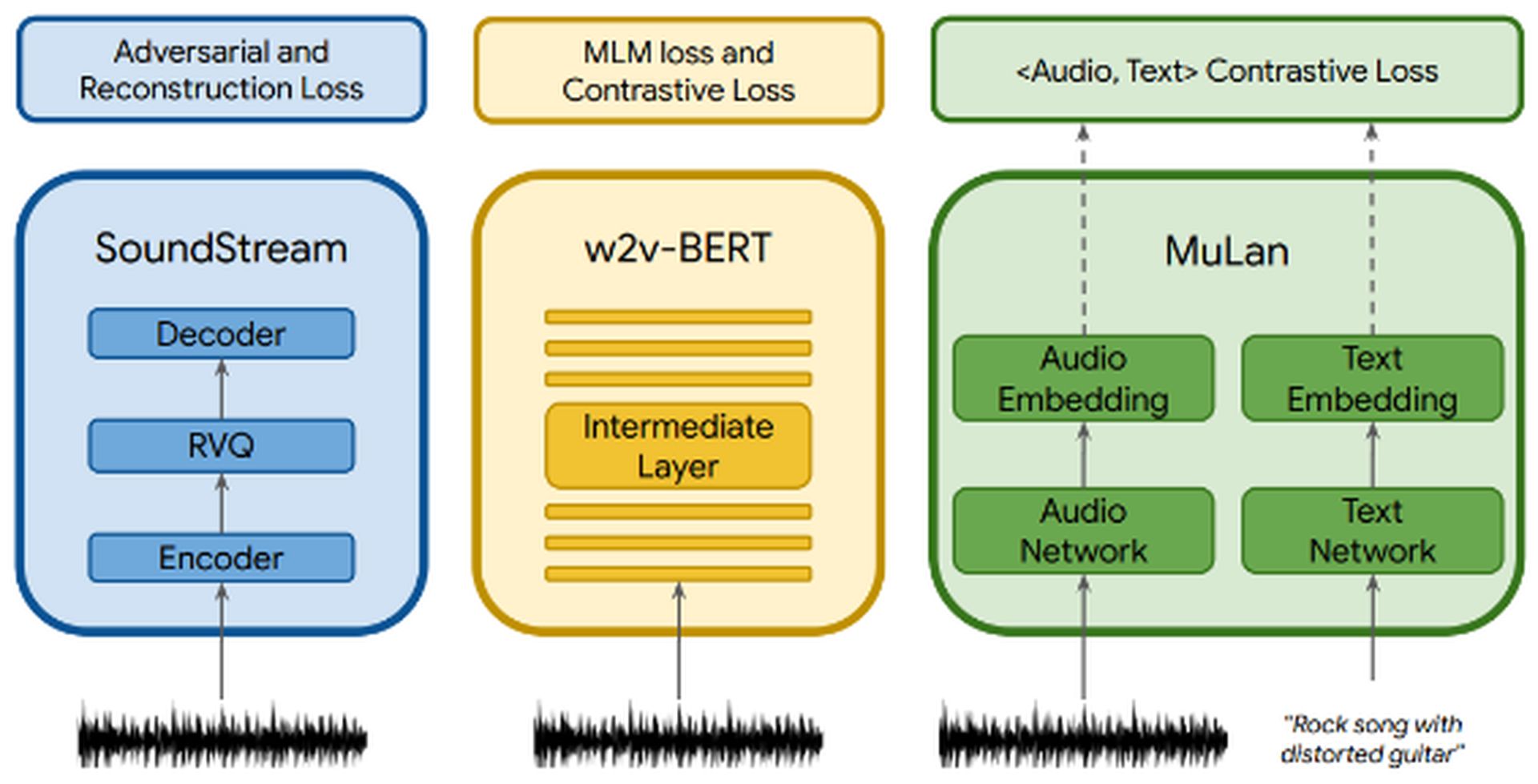
MusicLM leverages AudioLM’s multi-stage autoregressive modeling as its generative component, while also incorporating text conditioning. The audio file is passed through three components: SoundStream, w2v-BERT, and MuLan. SoundStream and w2v-BERT process and tokenize the input audio signal, while MuLan represents a joint embedding model for music and text. MuLan consists of two embedding towers, one for each modality (text and audio).
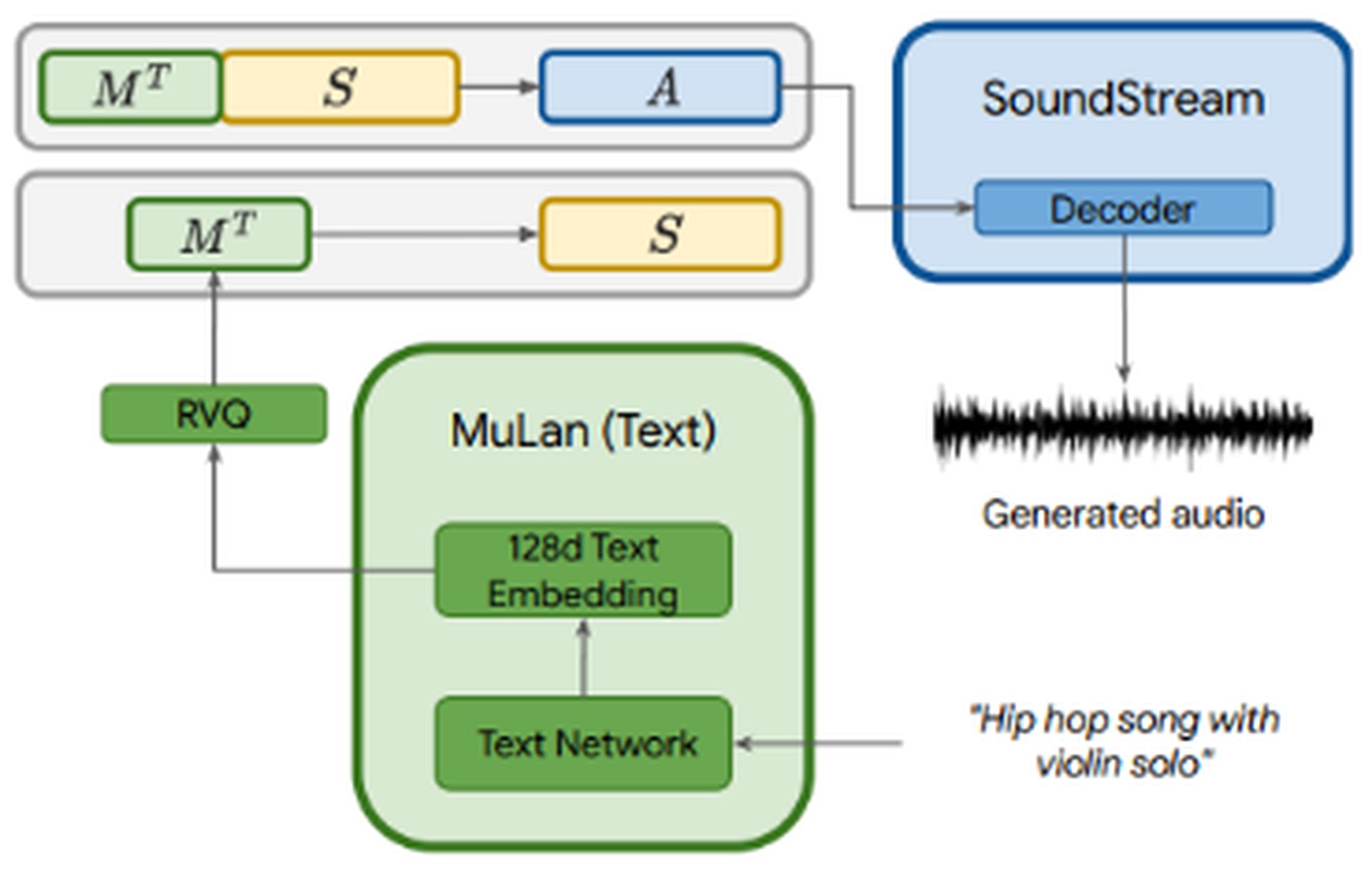
While the audio is fed into all three components, the text description is only fed into MuLan. The MuLan embeddings are quantized to provide a standardized representation based on discrete tokens for both the conditioning signal and the audio. The output from MuLan is then fed into the semantic modeling stage, where the model learns the mapping from audio tokens to semantic tokens. The subsequent process resembles that of AudioLM.
MusicLM, building upon AudioLM and MuLan, offers three key advantages:
- Music generation based on text descriptions.
- Incorporation of input melodies to extend functionality. For example, by providing a humming melody and instructing MusicLM to convert it into a guitar riff, the model can generate the desired output.
- Generation of long sequences for any musical instrument.
Dataset
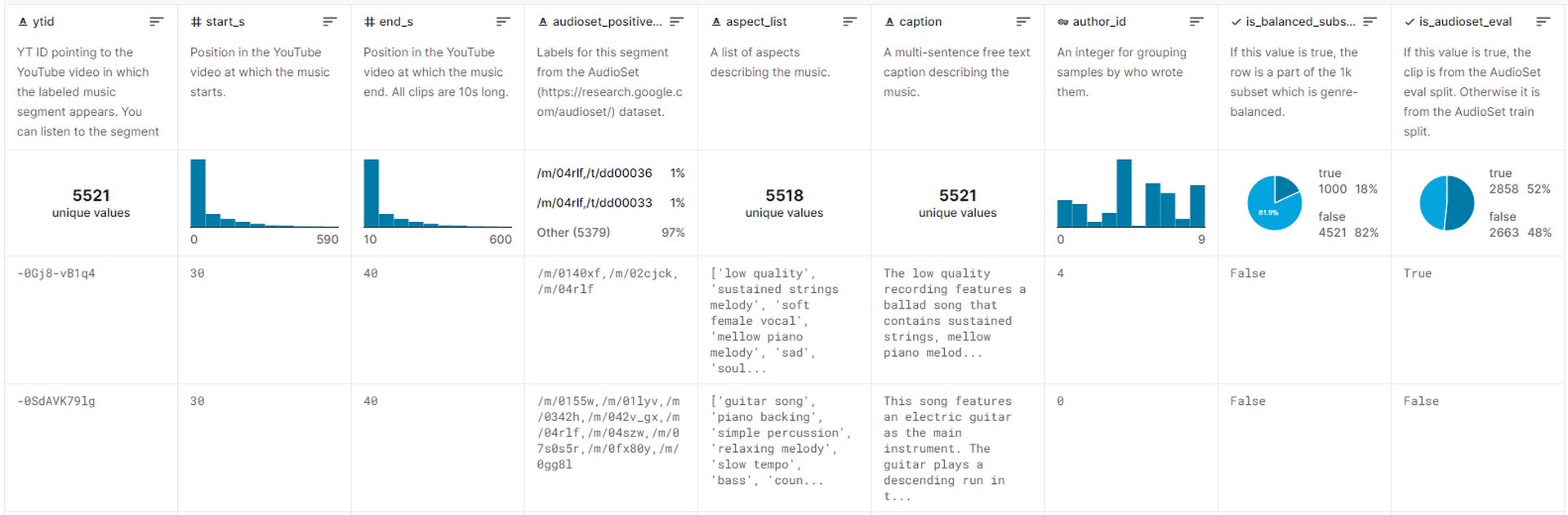
The dataset used to train MusicLM comprises approximately 5.5k music-text pairs. This dataset includes over 200,000 hours of music, accompanied by rich text descriptions provided by human experts. Google has released this dataset on Kaggle, named MusicCaps, and it can currently be accessed by the public.
Generating Music with MusicLM
Unfortunately, Google currently has no plans to distribute models related to MusicLM, citing the need for additional work. However, the white paper released by Google provides numerous examples demonstrating how music can be generated using text descriptions.
Here are several approaches to generating music with MusicLM:
- Rich captions: By providing detailed descriptions like “The main soundtrack of an arcade game. It is fast-paced and upbeat, with a catchy electric guitar riff. The music is repetitive and easy to remember, but with unexpected sounds like cymbal crashes or drum rolls,” MusicLM can create music that aligns with specific contexts and requirements.
- Long generation: This approach involves generating continuous and high-fidelity audio for extended periods, such as 5 minutes. By using prompts like “Heavy metal” or “soothing reggae,” users can obtain music within the desired genre and style.
- Story mode: A notable feature of MusicLM is the ability to generate a music sequence based on a series of text prompts. For instance, by specifying different time intervals and corresponding activities like “time to meditate (0:00-0:15)“, “time to wake up (0:15-0:30)“, and so on, users can orchestrate a musical journey.
- Text and melody conditioning: This approach allows users to produce music that adheres to a provided melody, such as a humming or whistling sequence while respecting the given text prompt. Essentially, it converts one audio sequence into the desired output.
- Painting caption conditioning: MusicLM can generate music based on painting descriptions. For example, by providing a description of Salvador Dali’s famous artwork “The Persistence of Memory“, the model can create music inspired by the painting’s concepts and imagery.
- Places: Descriptions of specific places or environments can serve as prompts for generating music. For instance, by using a description like “a sunny and peaceful time by the beach“, MusicLM can generate music that encapsulates the essence of that setting.
Additional examples include 10s audio generation from text, considering musician experience levels, epochs, and even accordion solos. MusicLM offers a versatile set of capabilities for generating music across various domains and scenarios.
The impressive capabilities of MusicLM in generating high-fidelity music showcase the remarkable potential of human creativity rather than solely relying on AI algorithms. However, this advancement also raises ethical concerns and may face resistance from the music community, similar to image-generating models like Dalle and ChatGPT.

Google researchers acknowledge the ethical issues associated with a system like MusicLM, including the potential for incorporating copyrighted content from training data into the generated songs. During experiments, they discovered that 1% of the music generated by the system directly replicated songs from its training data. This percentage was deemed too high to release MusicLM in its current form.
While it is unlikely that MusicLM will become a publicly available application in the near future, we can anticipate the emergence of open-sourced music models that may be reverse-engineered by independent developers. The future holds exciting possibilities for leveraging language models to enhance musical creativity and expression while ensuring the responsible and ethical use of these technologies.




{kind=link}