
The Google DreamBooth AI is here. Newly released technologies like OpenAI’s DALL-E 2 or StabilityAI’s Stable Diffusion and Midjourney are already taking the internet by storm. It is now time to customize the results. Yet how? Boston University and Google provided the responses, and we detailed it for you.
DreamBooth has the ability to recognize the topic of a picture, deconstruct it from its original context, and then precisely synthesize it into a new desired context. Additionally, it may be used with current AI picture generators. Learn more about AI-powered imagination by reading on.

Google DreamBooth AI explained
Google unveiled DreamBooth, a new text-to-image diffusion model. Google DreamBooth AI can create a broad variety of images of a user’s chosen topic in various conditions using a textual prompt as instruction.
DreamBooth, a revolutionary method for modifying heavily pre-trained text-to-image models, was created by a research team from Boston University and Google. Overall, the idea is rather simple: they want to expand the language-vision dictionary such that rare token IDs are connected to a specific topic that the user wants to create.
Key features of Google DreamBooth AI:
- With 3-5 photographs, DreamBooth AI may enhance a text-to-image model.
- Using DreamBooth AI, completely original photorealistic images of the subject may be produced.
- Additionally, the DreamBooth AI is capable of producing images of a subject from various perspectives.
The model’s major objective is to provide users with the tools necessary to create photorealistic representations of the instances of their chosen subject matter and connect them to the text-to-image diffusion model. As a result, this method appears to be effective for summarizing issues in a variety of circumstances.
Google’s DreamBooth takes a somewhat different approach from other recently released text-to-image tools like DALL-E 2, Stable Diffusion, and Midjourney by allowing users more control over the topic picture and then controlling the diffusion model using text-based inputs.
DreamBooth may also show the topic from various camera angles with just a few input photos. Artificial intelligence (AI) may foresee the subject’s qualities and synthesize them in text-guided navigation even if the input photos don’t give data on the topic from different viewpoints.
This model may also synthesis the photographs to create other moods, accessories, or color changes with the use of language cues. With these features, DreamBooth Google AI offers users even more personalization and creative freedom.

The DreamBooth article “DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation” claims that they provide one novel issue and approach:
- Subject-driven generation is a fresh issue.
Given a few hurriedly shot images of the subject, the goal is to create new representations of the subject in various settings while preserving high fidelity to its core visual characteristics.
Applications of the Google DreamBooth AI
The top Google DreamBooth AI applications are as follows:
- Recontextualization
- Art renditions
- Expression manipulation
- Novel view synthesis
- Accessorization
- Property modification
Are you prepared to part ways with PhotoShop? Let’s examine them more closely using the instructive pictures created by Nataniel Ruiz and the DreamBooth crew.
Recontextualization
By feeding a phrase including the unique identifier and the class noun to the trained model, DreamBooth AI may create unique pictures for a certain subject instance. Instead of modifying the background, DreamBooth AI may produce the subject in innovative, previously unseen postures, articulations, and scene structure. realistic shadows and reflections, as well as the subject’s interaction with adjacent objects. This shows that their strategy offers more than merely extrapolating or retrieving pertinent information.

Art renditions
If given the option to choose between “a statue of a [V] [class noun] in the style of [great sculptor]” and “a painting of a [V] [class noun] in the style of [famous painter],” which would you choose? Using DreamBooth AI, original creative representations may be created.

In particular, this task is different from style transfer, which preserves the semantics of the source scene while applying the style of another picture to the original scene. In contrast, depending on the creative style, the AI may achieve large scene changes with subject instance details and identity preservation.
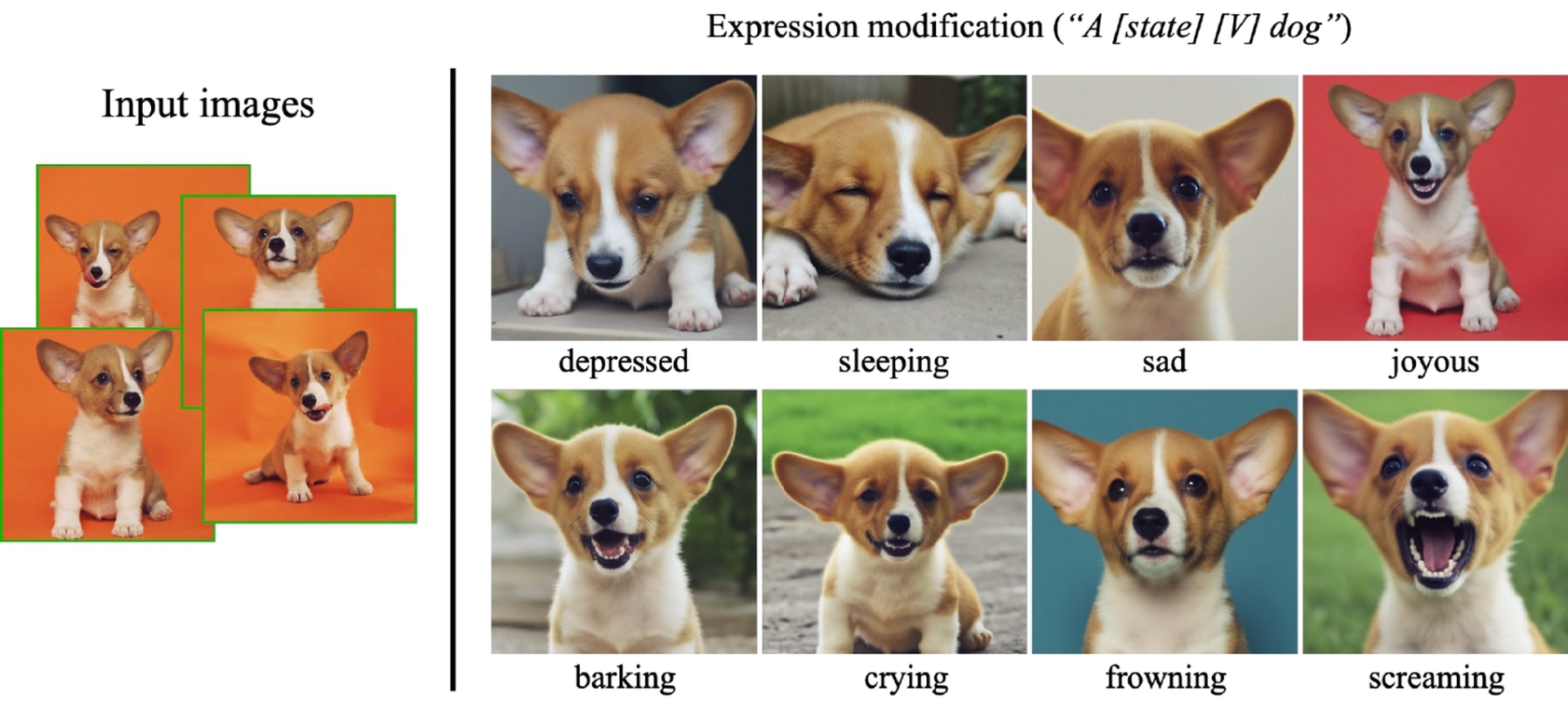
Expression manipulation
With the help of Google DreamBooth AI’s method, new pictures of the subject may be produced with different facial expressions from those in the original set of pictures.
Novel view synthesis
Google DreamBooth AI may depict the topic from a number of unique perspectives. For instance, DreamBooth AI may produce fresh images of the same cat using various camera angles, replete with dependably detailed fur patterns.
Despite the model just having four frontal photographs of the cat, DreamBooth AI is able to infer information from the class before creating these creative viewpoints, even though it has never seen this same cat from the side, from below, or from above.

Accessorization
The intriguing aspect of DreamBooth AI’s ability to embellish objects comes from the generation model’s strong compositional prior. For illustration, the model is prompted with a sentence of the form “a [V] [class noun] wearing [accessory]”. This makes it possible for us to attach various objects on the dog in an appealing way.

Property modification
DreamBooth AI is capable of changing the properties of the subject instance. A color adjective could be used in the example sentence “a [color adjective] [V] [class noun]”. This might result in fresh, vivid instances of the topic. There are a few requirements, but these characteristics also explain how to utilize DreamBooth AI.

Using the Google DreamBooth AI?
The DreamBooth AI technique takes as input a small number of photographs (usually 3-5 images are adequate) of a subject (for instance, a particular dog) and the class name associated with it (for instance, “dog”). It then produces a text-to-image model that has been tweaked and “personalized” and encodes a unique identity for the topic. To synthesize the topics in diverse contexts, DreamBooth AI may then insert the distinctive identification at inference into various phrases. Given three to five images of the subject, you may adjust a text-to-image diffusion in two steps:
- A text prompt with a particular code and the name of the class the subject belongs to (for instance, “a picture of a [T] canine”) will be used to enhance the low-resolution text-to-image model. In addition, they use a class-specific prior preservation loss, which leverages the model’s semantic prior on the class and encourages it to generate a range of examples that are members of the subject’s class by putting the class name in the text prompt (for example, “a picture of a dog”).
- We achieve great fidelity by tuning the super-resolution components using pairs of low- and high-resolution photographs from our input image set.
The first Dreambooth was made using Imagen‘s text-to-image paradigm. The model and weights from Imagen, however, are not available. However, using a few examples, Dreambooth on Stable Diffusion enables users to adjust a text-to-image model.
How to use Google Dreambooth AI on Stable Diffusion?
To utilize DreamBooth AI on Stable Diffusion, adhere to the following steps:
- Follow the setup instructions in the Textual Inversion repository or the original Stable Diffusion repository to set up your LDM environment.
- To fine-tune a stable diffusion model, you must receive the pre-trained stable diffusion models and adhere to their instructions. You may download weights from HuggingFace.
- Prepare a series of images for regularization as required by Dreambooth’s fine-tuning method.
- You may practice by using the following command:
|
1
2
3
4
5
6
7
8
|
python main.py --base configs/stable-diffusion/v1-finetune_unfrozen.yaml -t --actual_resume /path/to/original/stable-diffusion/sd-v1-4-full-ema.ckpt -n <job name> --gpus 0, --data_root /root/to/training/images --reg_data_root /root/to/regularization/images --class_word <xxx> |
Generation
After training, the command can be used to get personalized examples.
|
1
2
3
4
5
6
7
|
python scripts/stable_txt2img.py --ddim_eta 0.0 --n_samples 8 --n_iter 1 --scale 10.0 --ddim_steps 100 --ckpt /path/to/saved/checkpoint/from/training --prompt "photo of a sks <class>" |
In particular, class> is the class word—class word for training—and sks is the identifier (which, if you desire to alter it, should be replaced by your choice). For further information, visit the GitHub page for DreamBooth Stable Diffusion.
Limitations of the Dreambooth AI
The limitations of DreamBooth AI are as follows:
- Language drift
- Overfitting
- Preservation loss
Let’s examine them more closely.
Language drift
Producing iterations in the topic with a high degree of detail is hindered by the command prompt. DreamBooth can change the topic’s context, however there are issues with the frame if the model wishes to change the actual subject.
Overfitting
Another issue is when the output picture is overfitted onto the original image. The subject might not be assessed or might be combined with the context of the uploaded images if there aren’t enough input photos. This also occurs when a context for an odd generation is asked.
Preservation loss
The inability to synthesize pictures of rarer or more complex topics as well as variable subject fidelity, which can result in hallucinogenic shifts and discontinuous qualities, are further limitations. The input context is frequently included in the topic of the input images.

Societal impact of the AI
The DreamBooth project’s objective is to provide users with a practical tool for synthesizing personal topics (animals, objects) in a variety of settings. While standard text-to-image algorithms may be biased towards specific aspects when synthesising images from words, it helps the user to better recreate their chosen subjects. However, malicious parties may try to trick users by employing similar images. Various generative model methods or content modification techniques exhibit this pervasive issue.
Conclusion
The majority of text-to-image models need millions of parameters and libraries to create outputs from a single text input. DreamBooth makes it easier for users to obtain content and use it by simply needing the input of three to five topic images together with a written backdrop.
The topic’s distinctive qualities may therefore be preserved while the trained model reuses the materialistic aspects of the subject learnt from the images to replicate them in other settings and viewpoints. Most text-to-image conversion algorithms rely on certain keywords and may prioritize specific attributes when showing images. Users of DreamBooth may produce photorealistic results by seeing their chosen person in a unique environment or scenario. So, stop waiting now. Try it now!
We hope that you enjoyed this article on how to use Google Dreambooth AI on Stable Diffusion. If you did, we are sure that you will also enjoy reading some of our other articles, such as DALL-E 2 has introduced outpainting: AI imagines beyond borders, or Stable Diffusion AI art generator: Prompts, examples, and how to run.




{kind=link}