
Unveiled at the OpenAI Dev Day, the GPT-4 Turbo brings a major leap forward from the original GPT-4. It comes packed with improved capabilities, cost-effectiveness, and a beefed-up 128K context window. This means users can expect more detailed and insightful text outputs, with better overall coherence and consistency in the generated content thanks to the increased memory capacity.
One standout feature of the GPT-4 Turbo is that it offers all these advancements at a lower price compared to its predecessor, the GPT-4. This smart pricing move has the potential to open up access to cutting-edge AI technology, paving the way for a surge of innovative AI-powered applications and solutions across various industries.
What does GPT-4 Turbo offer to the table?
GPT-4 Turbo and the OpenAI Assistants API are game-changers for developers looking to create customized AI applications. The streamlined integration of goals and the ability to utilize various models and tools give developers the power to craft AI applications tailored to a wide range of tasks. These tasks can span from everyday chores like scheduling meetings to more complex endeavors like composing emails or generating original content.


Currently in its early access stage, the Assistants API holds tremendous promise for transforming how we interact with digital tools. Imagine a future where AI assistants are seamlessly woven into the fabric of our daily lives, efficiently handling personal tasks or smoothly managing business operations.
GPT-4 Turbo pricing
OpenAI has set an appealingly affordable pricing model for this innovative service. It’s $0.01 for every 1,000 input tokens (which roughly translates to about 750 words), and $0.03 for every 1,000 output tokens. In this context, “tokens” refer to text snippets. For example, the word “fantastic” is broken down into segments like “fan,” “tas,” and “tic.” This token-based system applies to both the data fed into the model and the responses generated by it. Additionally, the cost for image processing with GPT-4 Turbo will vary based on the dimensions of the image, with a 1080×1080 pixel image costing $0.00765.
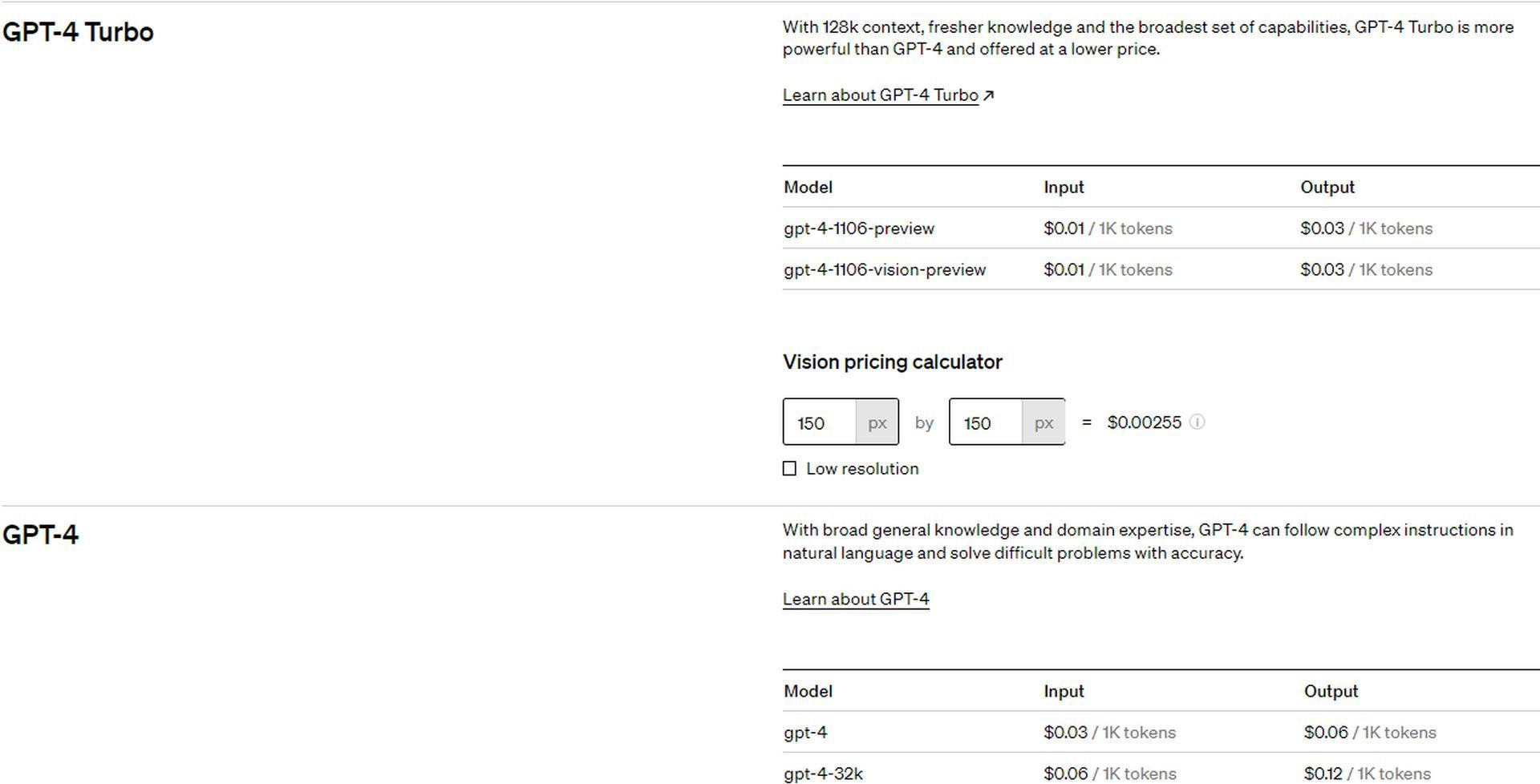
Here’s a more detailed table:
- GPT-4 Turbo 8K:
- Input price: $0.03
- Output price: $0.06
- GPT-4 Turbo 128K:
- Input price: $0.01
- Output price: $0.03
- GPT-3.5 Turbo 4K:
- Input price: $0.0015
- Output price: $0.002
- GPT-3.5 Turbo 16K:
- Input price: $0.003
- Output price: $0.004
- GPT-3.5 Turbo fine-tuning 4K and 16K:
- Training: $0.008
- Input price for 4K: $0.012
- Input price for 16K: $0.003
Similar to its predecessors, GPT-4 Turbo functions as a sophisticated statistical tool designed for word prediction. It’s been trained on a massive amount of data primarily sourced from the web, allowing it to determine the likelihood of word sequences. It takes into consideration not only the patterns of language but also the underlying semantic context.
While GPT-4’s training covered web content up until September 2021, GPT-4 Turbo expands its knowledge horizon to April 2023. This extension in temporal awareness ensures that inquiries about more recent events, up until the updated cut-off, are met with enhanced accuracy and relevance.
GPT-4 Turbo with Vision
GPT-4 Turbo with Vision represents a significant advancement in the GPT-4 Turbo lineup, as it has the ability to generate both text and visual content. This development opens up exciting possibilities for developers, allowing them to create AI applications that seamlessly combine language and imagery.
GPT-4 Turbo with Vision is set to revolutionize the creation of a new category of AI-powered creative tools. Imagine image editing suites or video editing platforms that leverage AI to help users create high-quality content with unprecedented ease and speed. This technology showcases the rapidly evolving capabilities of AI in enhancing human creativity and productivity.

Context window
GPT-4 Turbo brings a major upgrade in conversational AI models, thanks to its expanded context window. This window, measured in tokens, essentially determines how much text the model can refer to when generating responses. Models with smaller context windows can sometimes struggle with short-term memory, leading to conversations veering off track or encountering difficulties.
With an impressive context window of 128,000 tokens, GPT-4 Turbo sets a new standard in the industry. This is four times larger than its predecessor, GPT-4, and surpasses other models like Claude 2 from Anthropic, which can handle up to 100,000 tokens. To put it in perspective, 128,000 tokens roughly equate to 100,000 words or about 300 pages of text. This provides the model with a substantial pool of information to draw from for coherent and relevant conversation.
Additionally, GPT-4 Turbo introduces a ‘JSON mode’ that ensures outputs are in valid JSON format. This is particularly useful for web applications in transmitting data from servers to clients for displaying on web pages, according to OpenAI. Alongside this, additional parameters are introduced to enhance the model’s ability to offer consistent completions and, for specialized uses, to log probabilities of the most likely output tokens. These features not only broaden the usefulness of GPT-4 Turbo but also elevate the accuracy and relevance of its outputs across a wide range of web-based applications.
GPT-4 Turbo performs better than our previous models on tasks that require the careful following of instructions, such as generating specific formats (e.g. ‘always respond in XML’). And GPT-4 Turbo is more likely to return the right function parameters.
-OpenAI

GPT-4 updates
OpenAI is committed to pushing the boundaries of GPT-4 beyond the introduction of GPT-4 Turbo. They’re taking steps to enhance the capabilities of their latest model by launching an experimental program that enables fine-tuning of GPT-4. This program builds upon the fine-tuning process used for GPT-3.5, incorporating even greater oversight and support from the OpenAI teams to tackle the intricate technical challenges involved. This shows their dedication to continuously refining and maximizing the potential of their AI models.
Preliminary results indicate that GPT-4 fine-tuning requires more work to achieve meaningful improvements over the base model compared to the substantial gains realized with GPT-3.5 fine-tuning.
-OpenAI.
OpenAI is going above and beyond to enhance the value for its current GPT-4 users. They’ve announced a substantial increase in the tokens-per-minute rate limit for all GPT-4 subscribers, all while keeping the existing price structure unchanged. The standard GPT-4 model, which provides an 8,000-token context window, will maintain its costs at $0.03 per input token and $0.06 per output token. Meanwhile, for those utilizing the more extensive 32,000-token context window variant of GPT-4, the rates will stay at $0.06 per input token and $0.012 per output token. This move is aimed at providing even more value to users without raising the price.

OpenAI’s commitment to fine-tuning and improved value for subscribers further solidifies their position at the forefront of AI innovation. These developments promise a brighter future for AI applications across industries, highlighting the potential of GPT-4 Turbo to lead the way in artificial intelligence.
Meanwhile, if you wish to learn more about the new introductions by OpenAI, make sure to check out our articles on the summary of OpenAI Dev Day and Custom GPTs, GPTstore, and GPT builder.
Featured image credit: OpenAI



