
OpenAI has introduced a groundbreaking leap in the realm of artificial intelligence with the debut of GPTBot—a sophisticated web crawler set to revolutionize AI technology.
This innovative stride not only promises to enhance the precision, capabilities, and safety of AI models but also sparks profound discussions concerning data ethics, ownership, and utilization in the digital era.

Emergence of GPTBot
The arrival of GPTBot brings a novel perspective to webmasters and content creators, offering a window into the traversal of their digital domains. Thorough documentation empowers webmasters to discern GPTBot’s interactions with their websites and affords them the option to regulate their access through the familiar robots.txt protocol.


The purposes of the new web crawler include:
- Enhancing AI model performance: The data collected is used to train and fine-tune AI models, such as the GPT series, to improve their performance. By exposing AI models to a diverse range of content from the web, they can learn to generate more accurate and contextually relevant responses, thereby improving their overall quality.
- Enriching language and understanding: The data gathered contributes to the AI model’s understanding of language patterns, context, and various domains of knowledge. This enrichment helps AI models generate more coherent, informed, and contextually appropriate text in response to user queries.
- Filtering and safety measures: The new web crawler is designed to filter out certain types of content, such as paywall-restricted sources, content that violates OpenAI’s policies, or sources that gather personally identifiable information. This ensures that the data collected is both ethical and aligned with OpenAI’s standards.
- AI research and development: The data collected contributes to ongoing AI research and development efforts. It aids in exploring new avenues for AI applications and advancements in natural language processing, which have implications for a wide range of industries and fields.
- Model evolution and iteration: As AI models evolve, they require continuous learning and adaptation. The data collected allows for iterative improvements to AI models, ensuring that they stay current and relevant in an ever-changing digital landscape.
GPTBot’s user-agent and functionality
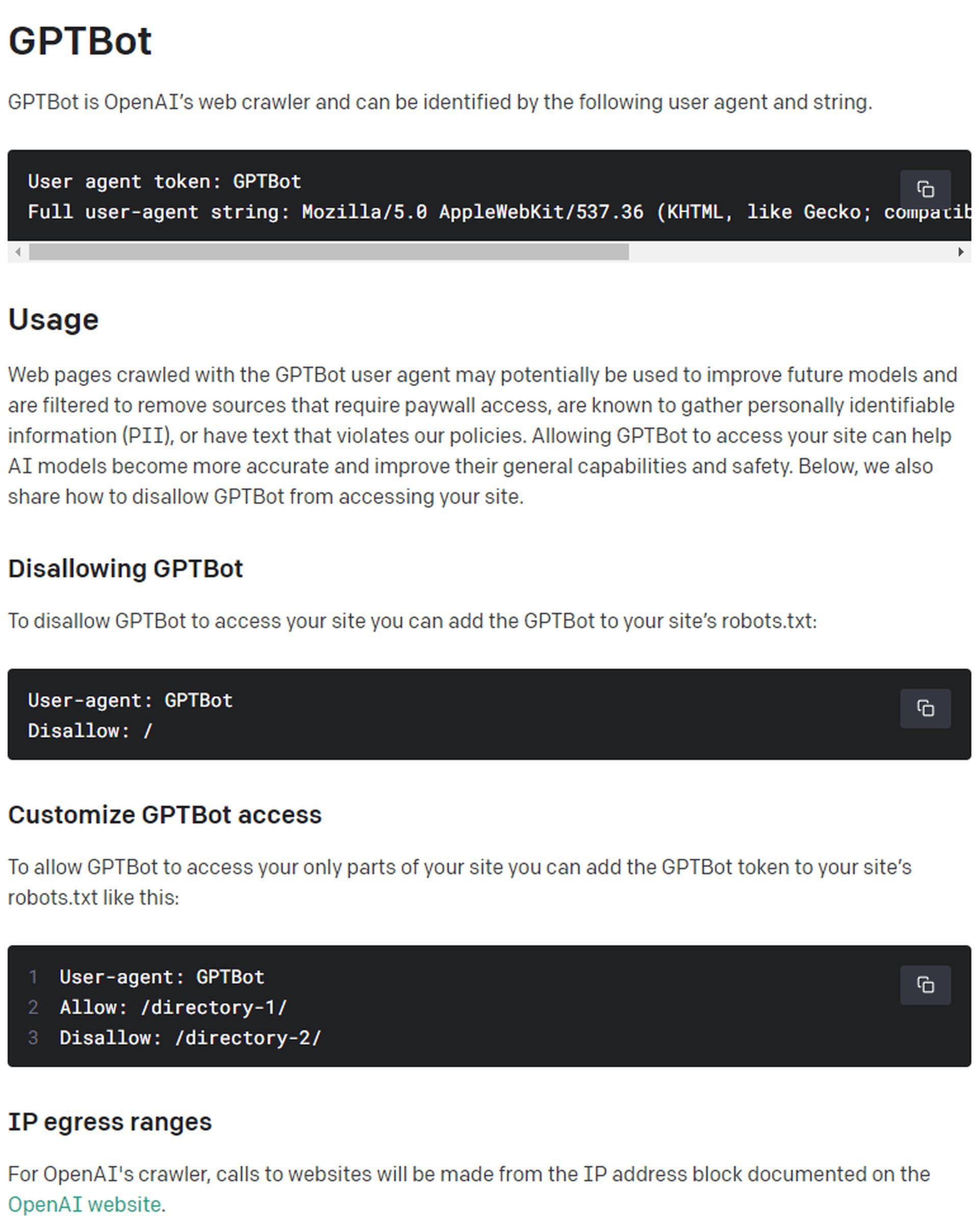
Distinguished by a distinctive user agent token and an exhaustive user-agent string, GPTBot embarks on a quest to traverse the digital landscape in search of invaluable data to enrich the AI ecosystem. Armed with the user-agent token “GPTBot” and the string “Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.0;+https://openai.com/gptbot),” this pioneering system aims to sieve outsources behind paywalls, content contravening OpenAI’s policies, and platforms gathering personally identifiable information.
The collaborative nature of GPTBot’s endeavor underscores the essence of this initiative. By granting access to their websites, webmasters contribute to a repository of data that enhances the capabilities of AI models on a grand scale. This step mirrors OpenAI’s commitment to cultivating a more accurate, adept, and secure AI landscape.

Customized access and ethical deliberations
In recognition of the diversity inherent in digital landscapes, OpenAI confers upon webmasters the autonomy to dictate the extent of GPTBot’s engagement with their websites. Through prudent modifications to their robots.txt files, webmasters wield the authority to either confine GPTBot’s access entirely or stipulate the directories it can navigate.
Curbing access is a straightforward process, entailing the inclusion of the following directives:
- User-agent: GPTBot Disallow: /
For a more nuanced approach that facilitates selective access, the following format can be adopted:
- User-agent: GPTBot Allow: /directory-1/ Disallow: /directory-2/
- Balancing Act: Legal, Ethical, and Ownership Considerations
OpenAI’s pioneering strides with GPTBot have ignited multifaceted debates within the tech community, accentuating the intricate interplay between legality, ethics, and innovation. While GPTBot does identify itself through the user agent, skeptics argue that its benefits are less tangible compared to traditional search engine crawlers. Concerns about using copyrighted content without proper attribution loom, and the absence of source citations in ChatGPT further compounds these worries.
The complexities extend to the handling of licensed media, raising queries about potential copyright infringement when integrated into model training. The possibility of AI-generated content being fed back into training cycles also surfaces as a potential challenge, potentially eroding model quality over time.

Future landscape: Ownership, transparency, and collaborative spirit
As GPTBot propels these profound dialogues, the tech community grapples with the intricate interplay between data ownership, fair use, and the motivations driving web content creation. While GPTBot’s adherence to robots.txt signifies a positive stride toward transparency, there is a growing desire for heightened clarity regarding its utilization of web data as AI products surge ahead.
With the unveiling of its new web crawler, OpenAI has sparked an intellectual renaissance transcending technology, ethics, and the digital frontier. This endeavor exemplifies OpenAI’s dedication to shaping a future where AI draws power not merely from algorithms, but from the collective wisdom and contributions of the digital realm. As GPTBot charts its course, the discourse surrounding it is poised to shape the trajectory of AI advancement, transparency, and equitable collaboration in the digital age.
Featured image credit: Levart_Photographer / Unsplash



