
Building on Whisper, researchers at Oxford are developing WhisperX for effective word-level timestamping in long-form speech transcriptions.
Due to the availability of extensive online datasets, weakly supervised and unsupervised training approaches have demonstrated outstanding performance on a variety of audio processing tasks, including voice recognition, speaker recognition, speech separation, and keyword spotting.

How do Whisper and WhisperX work?
Whisper, a speech recognition system created by Oxford researchers, makes use of this substantial information on a bigger scale. They show how weakly supervised pretraining of a basic encoder-decoder transformer can achieve zero-shot multilingual speech transcription on recognized benchmarks using 125,000 hours of English translation data and 680,000 hours of noisy speech training data in 96 additional languages.
While the majority of academic benchmarks consist of brief statements, in real-world contexts like meetings, podcasts, and videos, transcription of lengthy audio that may last for hours or minutes is frequently needed.
Transformer designs employed in automated speech recognition (ASR) models do not allow transcription of arbitrarily long input audio (up to 30 seconds in the case of Whisper) due to memory constraints.

Recent research employs heuristic sliding-window methods, which are error-prone due to incomplete audio, where some words may be missed or incorrectly transcribed if they are at the beginning or end of the input segment; and overlapping audio, which can result in inconsistent transcriptions when the model processes the same speech twice.
Whisper presents a buffered transcription technique that determines how far the input window should be shifted based on accurate timestamp prediction. Such a method is susceptible to severe drifting because timestamp inaccuracies in one window could compound into problems in subsequent windows.
They use a number of homemade heuristics to try and eradicate these errors, although they frequently are unsuccessful in doing so. Whisper’s linked decoding, which makes use of a single encoder-decoder to decode timestamps and transcriptions, is prone to the usual problems with auto-regressive language generation, notably hallucination and repetition.
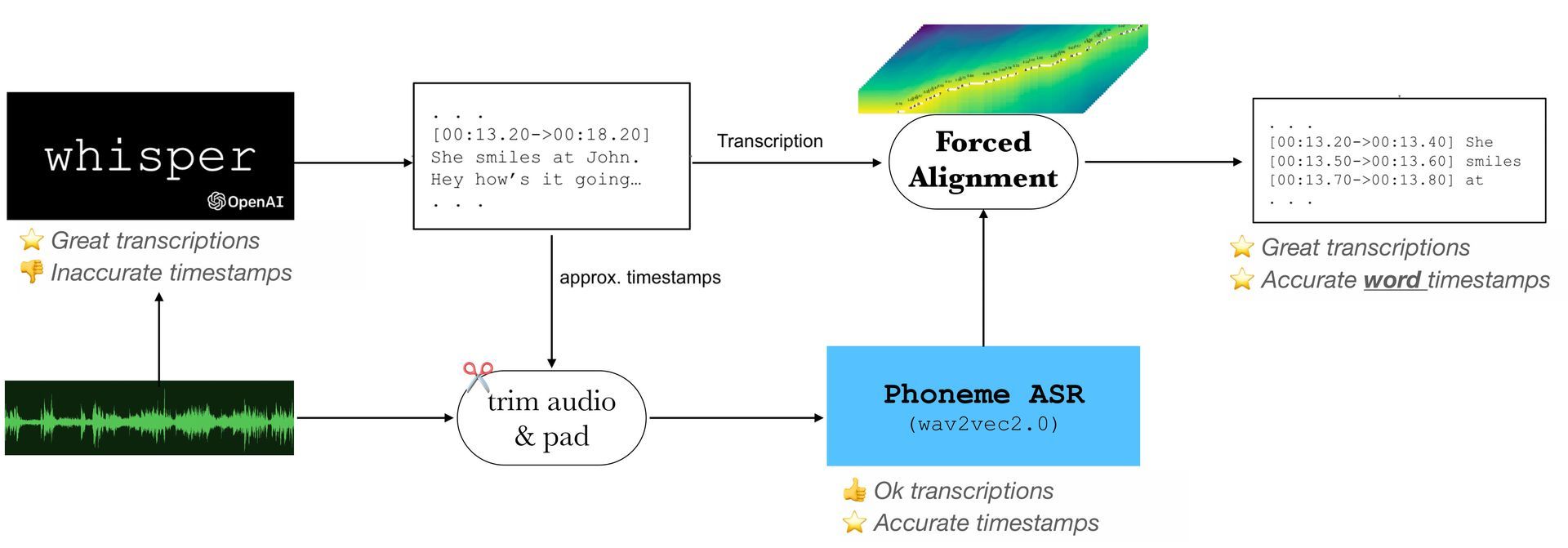
Long-form and other timestamp-sensitive activities like speaker diarization, lip-reading, and audiovisual learning are adversely affected by this, as well as buffered transcription.
The Whisper paper claims that a sizable portion of the training corpus consists of incomplete data (audio-transcription pairings lacking timestamp information), denoted by the token |nottimestamps|>. The performance of speech transcription is unintentionally sacrificed for less accurate timestamp prediction when scaling on imperfect and noisy transcription material.
As a result, when using additional modules, the speech and transcript must properly line up. In “forced alignment“, speech transcription and audio waveforms are synchronized at the word- or phoneme-level. The Hidden Markov Model (HMM) framework and the by-product of possible state alignments are frequently used in the training of the acoustic phone models.
External boundary correction models are frequently used to correct the timestamps for these words or phone numbers. Due to the rapid expansion of deep learning-based methodologies, some recent studies use deep learning techniques for forced alignment, such as applying a bi-directional attention matrix or CTC segmentation with the end-to-end trained model.
Further improvement could be achieved by combining a state-of-the-art ASR model with a straightforward phoneme recognition model, both of which were built using significant large-scale datasets.
When WhisperX comes into the picture
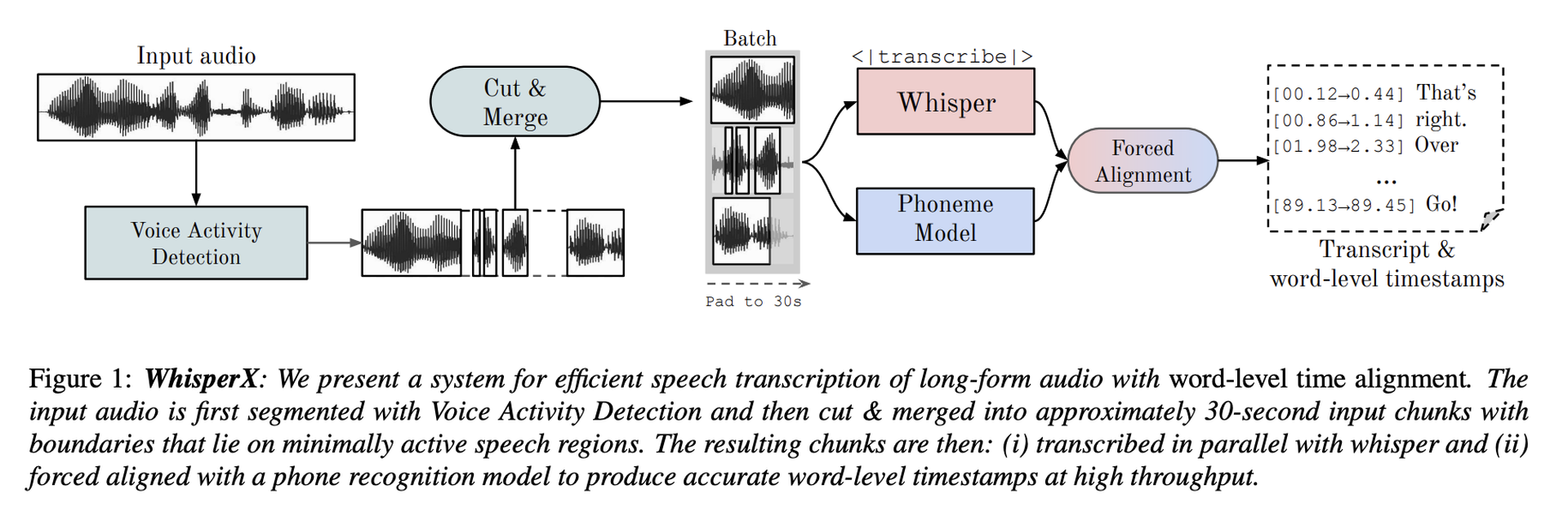
They propose WhisperX, a technique for accurate speech transcription of lengthy recordings with precise word-level timestamps, as a solution to these issues. In addition to whispered transcription, it also comprises the following three steps:
- Using an external Voice Activity Detection (VAD) model to pre-segment the incoming audio.
- The resulting VAD segments are divided and merged into roughly 30-second input chunks with bounds on speech regions with the least amount of activity.
- To deliver accurate word-level timestamps, they demand alignment with an external phoneme model.
With the rise of AI and text-based AI chatbots, text-to-speech and speech recognition programs are on high demand. Just this week, ChatGPT video chat app Call Annie AI has been released in an attempt to capitalize on this rising demand. Although, WhisperX’s future is not yet entirely clear regarding its possibilities, we could say that it’s definitely worth to keep track of its progress.




{kind=link}