
MiniGPT-4 is an advanced language model that utilizes the Vicuna language decoder, pre-trained vision component of BLIP–2, and a single projection layer to achieve high computational efficiency, but may have limitations in reasoning capacity and detecting detailed textual information in pictures.
MiniGPT-4 is a new open-source AI model designed to perform complex vision-language tasks, such as generating precise and detailed image descriptions, creating websites using handwritten text instructions, and solving unusual visual phenomena.
Developed by a team of Ph.D. students from King Abdullah University of Science and Technology in Saudi Arabia, MiniGPT-4 utilizes the transformer architecture to power its language decoding abilities, similar to its predecessor GPT-4.

To test Mini-GPT, simply click on the link provided. This will take you to a webpage where you can input text prompts and generate output based on Mini-GPT’s predictions. Mini-GPT uses the same deep learning techniques and language models as the larger GPT models but with fewer parameters and a reduced computational footprint.
What is MiniGPT-4?
GPT-4 is the latest Large Language Model from OpenAI, and it is known for its exceptional performance in emulating human language.
However, the reasons behind its impressive abilities are still largely unknown. Researchers hypothesize that GPT-4’s success may be due to the use of a more advanced Large Language Model, which led to the creation of MiniGPT-4.
How MiniGPT-4 works?
MiniGPT-4 uses Vicuna, an advanced LLM built upon LLaMA, as its language decoder. The model utilizes the pre-trained vision component of BLIP–2 and a single projection layer to align encoded visual features with the Vicuna language model.
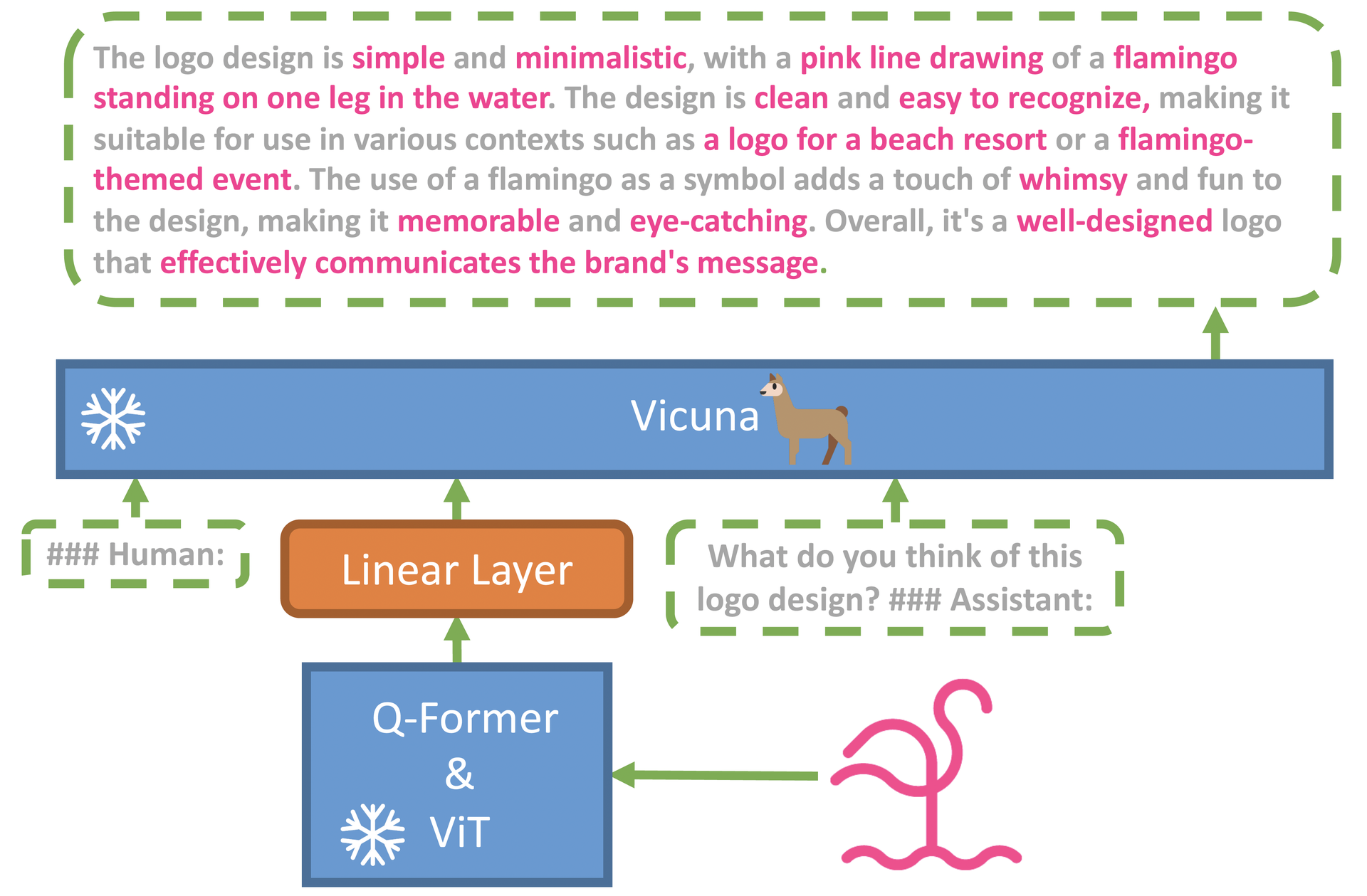
This approach has led to impressive results in several areas of application, including identifying problems from picture input, generating product advertisements and detailed recipes by observing images, and coming up with rap songs inspired by images. The model can also retrieve facts about people, movies, or art directly from images.
One of the most significant advantages of MiniGPT-4 is its high computational efficiency. The model requires only approximately 5 million aligned image-text pairs for training a projection layer, and training the model takes approximately 10 hours on four A100 GPUs.
This makes it highly accessible to researchers and developers who may not have access to the most advanced hardware.
However, the team notes that training the model with public datasets alone can result in repeated phrases or fragmented sentences. MiniGPT-4 requires a high-quality, well-aligned dataset to produce more natural and coherent language outputs.
Therefore, interested users should ensure that they have access to a reliable dataset before attempting to use the model.
Limits
Although MiniGPT-4 offers many sophisticated vision-language capabilities, it has significant limitations.
- Even with high-end GPUs, the model inference is currently sluggish, which might result in slow results.
- Because the model is based on LLMs, it inherits flaws like faulty reasoning capacity and imagining non-existent information.
- The model’s visual vision is restricted, and it may fail to detect detailed textual information in pictures.
Conclusion
MiniGPT-4 is an exciting development in the field of open-source AI models. Its exceptional multimodal generation capabilities and high computational efficiency make it an attractive tool for researchers and developers interested in exploring the potential of vision-language models.
Interested users can access the code, pre-trained model, and collected dataset to gain a deeper understanding of this promising development in the field of AI models.
Do you realize how bad can AI be? We described it in terms of Hollywood’s projection.




{kind=link}